Understanding tokens
We've mentioned "tokens" a few times without stopping to explain what they are. Let's do that now.
The OpenAI natural language models don't operate on words or characters as units of text, but on something in-between: tokens. A token may be a single character, or a fraction of a word, or an entire word. Many common words are represented by a single token, less common words are represented by multiple tokens.
When you enter text in the prompt box or generate a completion, a counter appears below that counts the total number of tokens in the box. (Note: the counter takes a few seconds to update if you're actively typing.)
How many tokens are in the following words?
"apple"
"hamburger"
"Skarsgård"
As a common word, "apple" requires only one token. The word "hamburger" requires three tokens: "ham", "bur" and "ger". Unless they are very common, proper names generally require multiple tokens. It's this token representation that allows AI models to generate words that are not in any dictionary, but without having to generate text on a letter-by-letter basis (which could easily result in gibberish).
Tip: OpenAI provides a useful tool for visualizing the tokens in text phrases. Try it out here: OpenAI Tokenizer.
The natural language models generate completions one token at a time, but the generated token is not deterministic. At each step, the model outputs a list of all possible tokens with associated weights. The API samples one token from this list, with heavily-weighted tokens more likely to be selected than the others.
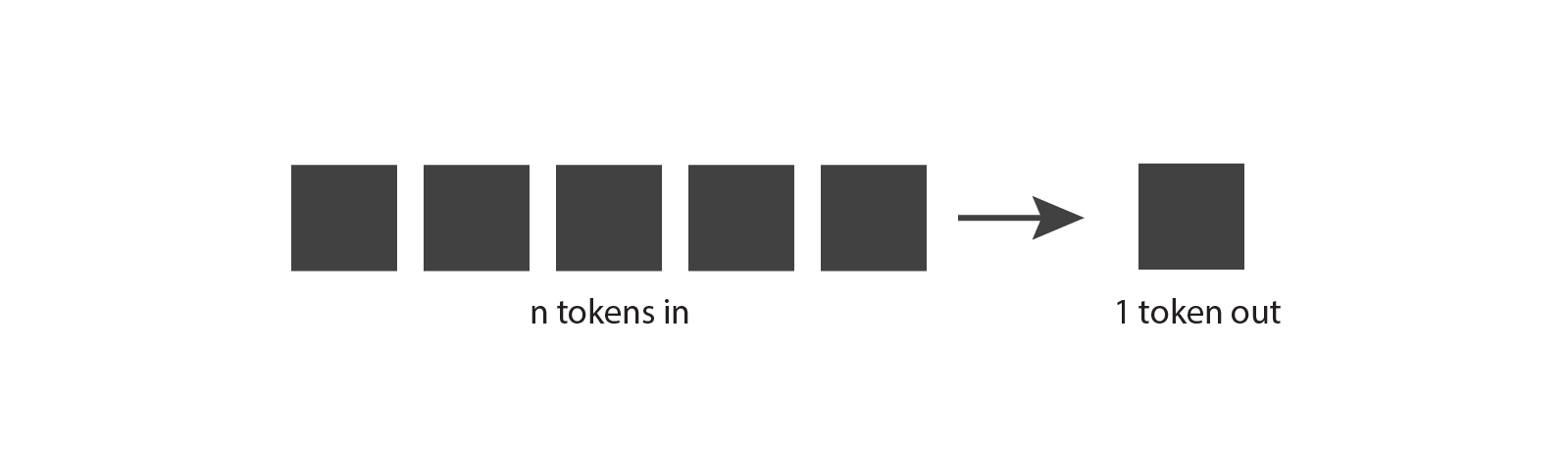
Then it adds that token to the prompt and repeats the process until the "Max length (tokens)" limit is met for the completion, or until the model generates a special token called a "stop token", which prevents further tokens from being generated. (This blog post by Beatriz Stollnitz explains the process in more detail.)
This is how the model generates completions of one or more words, and why those completions can change from invocation to invocation.
Observe the token generation process
To observe the completion generation process token-by-token, set the "Max length (tokens)" option to 1. Now enter a this prompt (feel free to replace the last letter with another of your choice):
Here is a long and unique name for a cat: J
Now, repeatedly click the Generate button. With each click, a new token is added to your prompt, which becomes the new prompt each time you click Generate.
Eventually, you will observe this pop-up: "No text was generated by the model. Consider modifying your prompt and parameters to improve response behavior". This occurs when the model's highest-weighted token is the "stop" token, which prevents any further generation. (This message will also appear if the generated token is whitespace. In that case, you can click Generate again until a non-whitespace token is generated.)
Reset the token limit to 1000 before continuing.
Token limits
Every model has a limit on the number of tokens it can process in a single request. For text-davinci-003 it is 4,096 tokens, and you can see the limits for other models here. Note that this limit applies to the total number of tokens in the prompt and the completion: as we've seen, the completion is added to the prompt before the next token is generated, and both must be contained within the token limit.
Newer models like gpt-4-32k have much larger token limits: up to 32,768 tokens. This not only allows for longer completions but also much larger prompts. This is particularly useful for prompt engineering, as we'll see later.